Deep neural networks have evolved to be the state-of-the-art technique for many machine learning applications. For example, large language models (LLMs) like GPT and LLaMA are transformative in natural language processing and convolutional neural networks (CNNs) are effective in image recognition, offering excellent performance across a range of tasks. However, these algorithms require massive computational resources and carbon footprint, making them unsuitable for direct deployment on edge devices, such as laptops, mobile phones and microcontrollers (MCUs). There is a critical need to create tiny machine learning (TinyML) that can run efficiently in on-device environments, enabling advanced AI capabilities on personal devices to protect user/data privacy without relying on cloud computing. This project aims to address these issues by innovating model compression techniques as well as high-performance system design for efficient AI computing. In this project, we propose multiple techniques, including AWQ, SmoothQuant, PockEngine, MCUNetV1, MCUNetV2, MCUNetV3, and TinyTL to largely shrink AI model size and to deploy and run efficiently on edge devices.

===============================================================================================================
Ji Lin*, Jiaming Tang*, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han
Massachusetts Institute of Technology, Tsinghua University, MIT-IBM Watson AI Lab
MLSys 2024
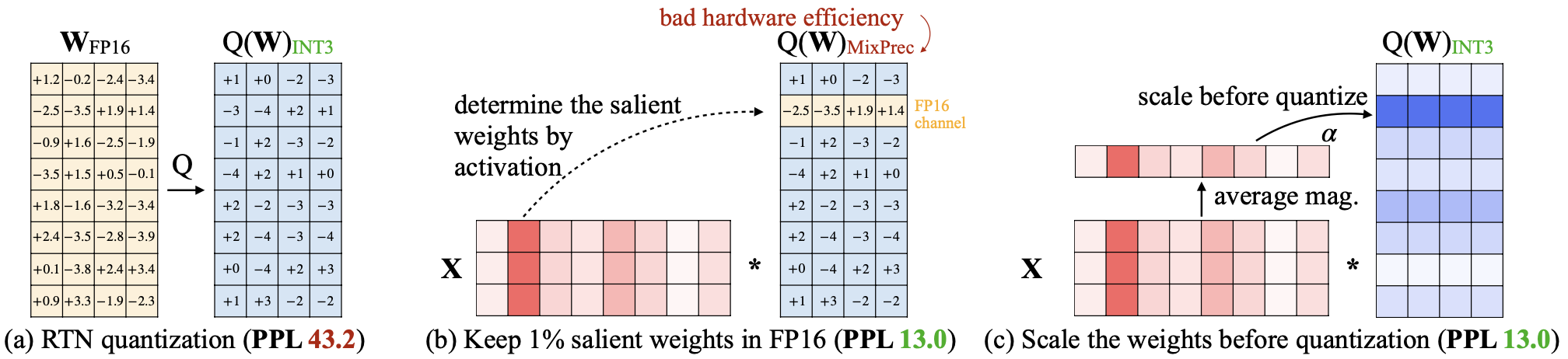
Large language models (LLMs) have shown excellent performance on various tasks, but the astronomical model size raises the hardware barrier for serving (memory size) and slows down token generation (memory bandwidth). In this paper, we propose Activation-aware Weight Quantization (AWQ), a hardware-friendly approach for LLM low-bit weight-only quantization. Our method is based on the observation that weights are not equally important: protecting only 1% of salient weights can greatly reduce quantization error. We then propose to search for the optimal per-channel scaling that protects the salient weights by observing the activation, not weights. AWQ does not rely on any backpropagation or reconstruction, so it can well preserve LLMs' generalization ability on different domains and modalities, without overfitting to the calibration set. AWQ outperforms existing work on various language modeling and domain-specific benchmarks. Thanks to better generalization, it achieves excellent quantization performance for instruction-tuned LMs and, for the first time, multi-modal LMs. Alongside AWQ, we implement an efficient and flexible inference framework tailored for LLMs on the edge, offering more than 3x speedup over the HuggingFace FP16 implementation on both desktop and mobile GPUs. It also democratizes the deployment of the 70B Llama-2 model on mobile GPU (NVIDIA Jetson Orin 64GB).
===============================================================================================================
Guangxuan Xiao*, Ji Lin*, Mickael Seznec, Hao Wu, Julien Demouth, Song Han
Massachusetts Institute of Technology, NVIDIA
ICML 2023
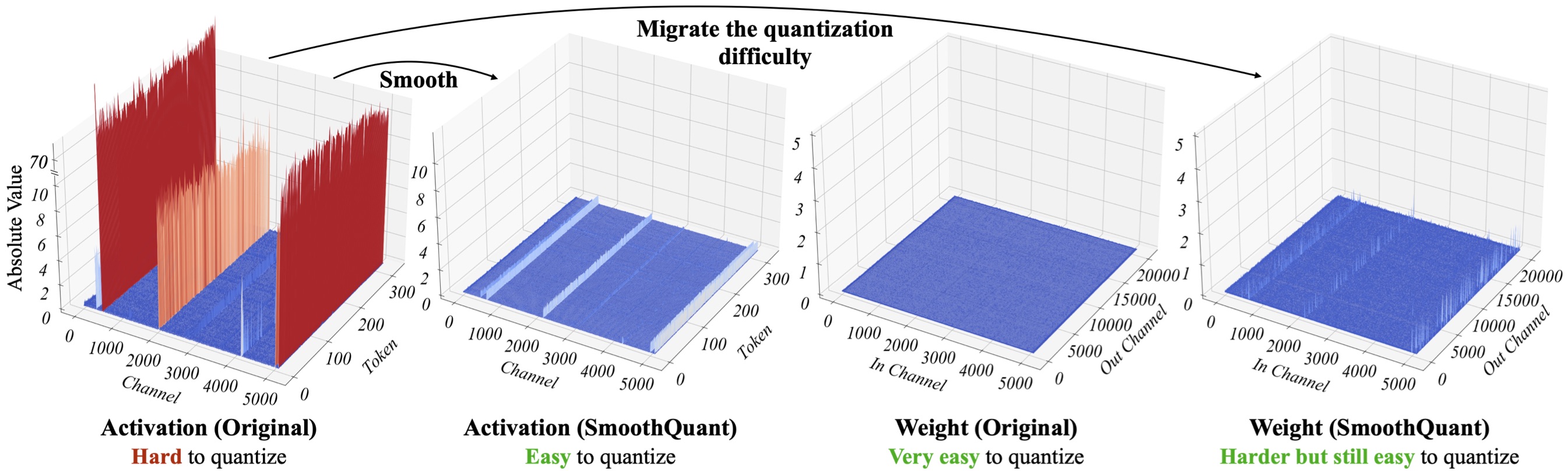
Large language models (LLMs) show excellent performance but are compute- and memory-intensive. Quantization can reduce memory and accelerate inference. However, existing methods cannot maintain accuracy and hardware efficiency at the same time. We propose SmoothQuant, a training-free, accuracy-preserving, and general-purpose post-training quantization (PTQ) solution to enable 8-bit weight, 8-bit activation (W8A8) quantization for LLMs. Based on the fact that weights are easy to quantize while activations are not, SmoothQuant smooths the activation outliers by offline migrating the quantization difficulty from activations to weights with a mathematically equivalent transformation. SmoothQuant enables an INT8 quantization of both weights and activations for all the matrix multiplications in LLMs, including OPT, BLOOM, GLM, MT-NLG, and LLaMA families. We demonstrate up to 1.56x speedup and 2x memory reduction for LLMs with negligible loss in accuracy. SmoothQuant enables serving 530B LLM within a single node. Our work offers a turn-key solution that reduces hardware costs and democratizes LLMs.
===============================================================================================================
Ligeng Zhu, Lanxiang Hu, Ji Lin, Wei-Chen Wang, Wei-Ming Chen, Chuang Gan, Song Han
Massachusetts Institute of Technology, UCSD, MIT-IBM Watson AI Lab, NVIDIA
MICRO 2023

On-device learning and efficient fine-tuning enable continuous and privacy-preserving customization (e.g., locally fine-tuning large language models on personalized data). However, existing training frameworks are designed for cloud servers with powerful accelerators (e.g., GPUs, TPUs) and lack the optimizations for learning on the edge, which faces challenges of resource limitations and edge hardware diversity. In this paper, we introduce PockEngine: a tiny, sparse and efficient engine to enable fine-tuning on various edge devices. PockEngine supports sparse backpropagation: it prunes the backward graph and sparsely updates the model with measured memory saving and latency reduction while maintaining the model quality. Secondly, PockEngine is compilation first: the entire training graph (including forward, backward and optimization steps) is derived at compile-time, which reduces the runtime overhead and brings opportunities for graph transformations. PockEngine also integrates a rich set of training graph optimizations, thus can further accelerate the training cost, including operator reordering and backend switching. PockEngine supports diverse applications, frontends and hardware backends: it flexibly compiles and tunes models defined in PyTorch/TensorFlow/Jax and deploys binaries to mobile CPU/GPU/DSPs. We evaluated PockEngine on both vision models and large language models. PockEngine achieves up to 15x speedup over off-the-shelf TensorFlow (Raspberry Pi), 5.6x memory saving back-propagation (Jetson Orin). Remarkably, PockEngine enables fine-tuning LLaMA2-7B on NVIDIA Jetson Orin at 550 tokens/s, 7.9x faster than PyTorch.
===============================================================================================================
Ji Lin, Ligeng Zhu, Wei-Ming Chen, Wei-Chen Wang, Song Han
Massachusetts Institute of Technology
IEEE Circuits and Systems Magazine 2023
Tiny machine learning (TinyML) is a new frontier of machine learning. By squeezing deep learning models into billions of IoT devices and microcontrollers (MCUs), we expand the scope of AI applications and enable ubiquitous intelligence. However, TinyML is challenging due to the hardware constraints: the tiny memory resource is difficult hold deep learning models designed for cloud and mobile platforms. There is also limited compiler and inference engine support for bare-metal devices. Therefore, we need to co- design the algorithm and system stack to enable TinyML. In this review, we will first discuss the definition, challenges, and appli- cations of TinyML. We then survey the recent progress in TinyML and deep learning on MCUs. Next, we will introduce MCUNet, showing how we can achieve ImageNet-scale AI applications on IoT devices with system-algorithm co-design. We will further ex- tend the solution from inference to training and introduce tiny on-device training techniques. Finally, we present future directions in this area. Today’s “large” model might be tomorrow’s “tiny” model. The scope of TinyML should evolve and adapt over time.
===============================================================================================================
Ji Lin, Wei-Ming Chen, Yujun Lin, John Cohn, Chuang Gan, Song Han
Massachusetts Institute of Technology, National Taiwan University, MIT-IBM Watson AI Lab
NeurIPS 2020
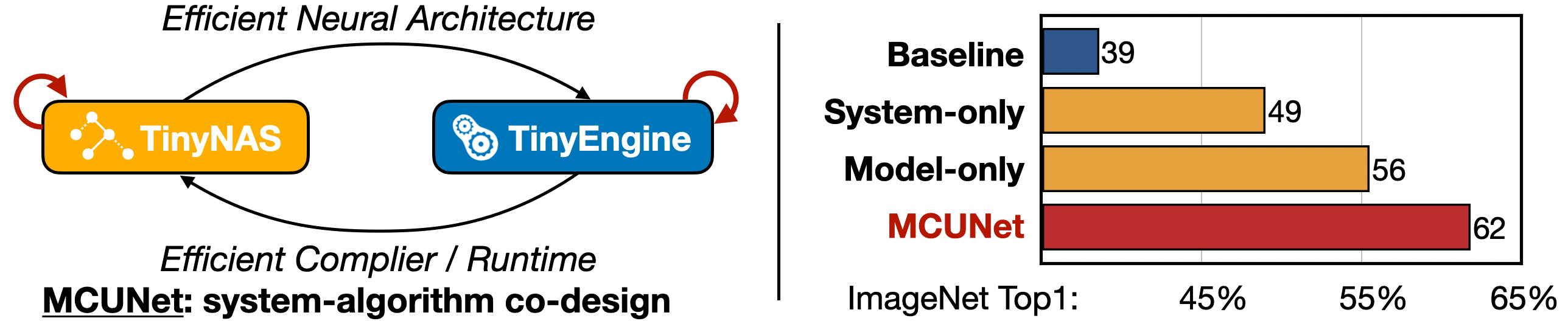
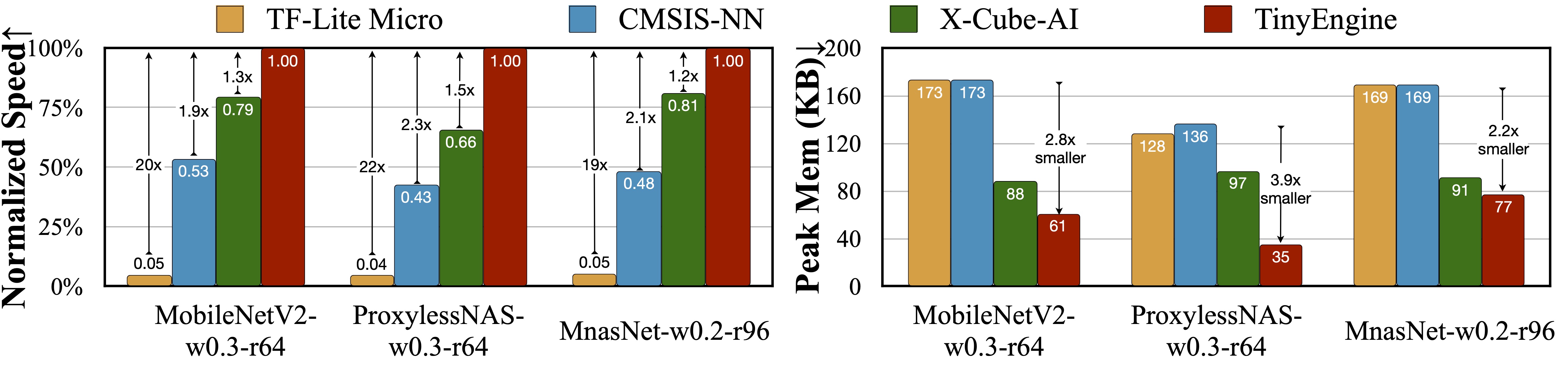
Machine learning on tiny IoT devices based on microcontroller units (MCU) is appealing but challenging: the memory of microcontrollers is 2-3 orders of magnitude smaller even than mobile phones. We propose MCUNet, a framework that jointly designs the efficient neural architecture (TinyNAS) and the lightweight inference engine (TinyEngine), enabling ImageNet-scale inference on microcontrollers.TinyNAS adopts a two-stage neural architecture search approach that first optimizes the search space to fit the resource constraints, then specializes the network architecture in the optimized search space. TinyNAS can automatically handle diverse constraints (i.e. device, latency, energy, memory) under low search costs. TinyNAS is co-designed with TinyEngine, a memory-efficient inference library to expand the search space and fit a larger model. TinyEngine adapts the memory scheduling according to the overall network topology rather than layer-wise optimization, reducing the memory usage by 3.4x, and accelerating the inference by 1.7-3.3x compared to TF-Lite Micro and CMSIS-NN. MCUNet is the first to achieves >70% ImageNet top1 accuracy on an off-the-shelf commercial microcontroller, using 3.5x less SRAM and 5.7x less Flash compared to quantized MobileNetV2 and ResNet-18. On visual&audio wake words tasks, MCUNet achieves state-of-the-art accuracy and runs 2.4-3.4x faster than MobileNetV2and ProxylessNAS-based solutions with 3.7-4.1x smaller peak SRAM. Our study suggests that the era of always-on tiny machine learning on IoT devices has arrived.
===============================================================================================================
Ji Lin, Wei-Ming Chen, Han Cai, Chuang Gan, Song Han
Massachusetts Institute of Technology, MIT-IBM Watson AI Lab
NeurIPS 2021
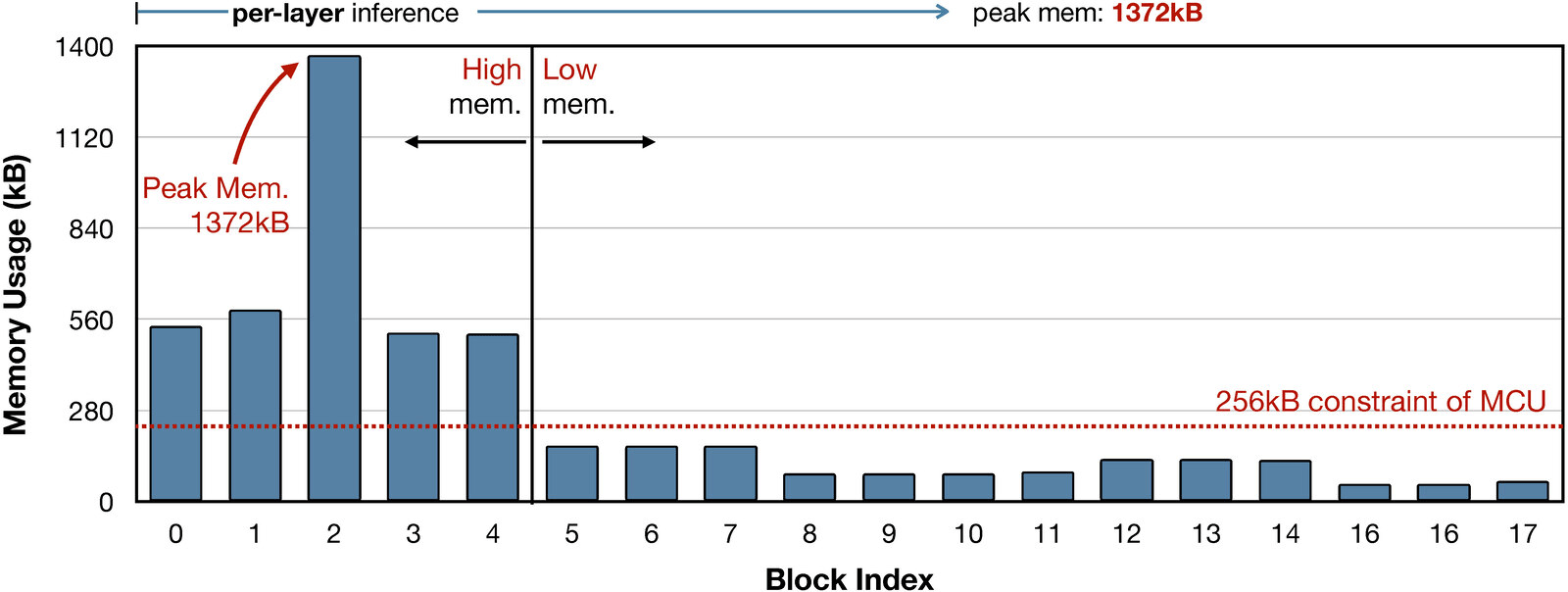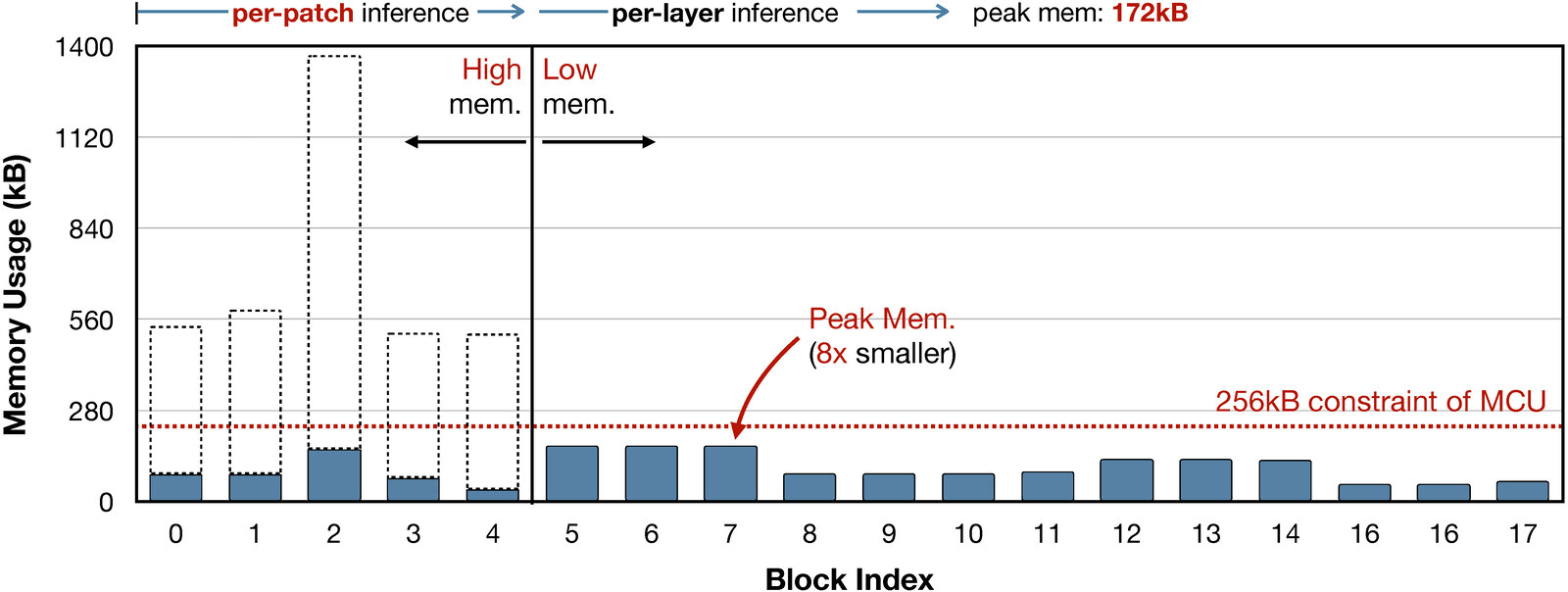
Tiny deep learning on microcontroller units (MCUs) is challenging due to the limited memory size. We find that the memory bottleneck is due to the imbalanced memory distribution in convolutional neural network (CNN) designs: the first several blocks have an order of magnitude larger memory usage than the rest of the network. To alleviate this issue, we propose a generic patch-by-patch inference scheduling, which operates only on a small spatial region of the feature map and significantly cuts down the peak memory. However, naive implementation brings overlapping patches and computation overhead. We further propose network redistribution to shift the receptive field and FLOPs to the later stage and reduce the computation overhead. Manually redistributing the receptive field is difficult. We automate the process with neural architecture search to jointly optimize the neural architecture and inference scheduling, leading to MCUNetV2. Patch-based inference effectively reduces the peak memory usage of existing networks by 4-8x. Co-designed with neural networks, MCUNetV2 sets a record ImageNet accuracy on MCU (71.8%), and achieves >90% accuracy on the visual wake words dataset under only 32kB SRAM. MCUNetV2 also unblocks object detection on tiny devices, achieving 16.9% higher mAP on Pascal VOC compared to the state-of-the-art result. Our study largely addressed the memory bottleneck in tinyML and paved the way for various vision applications beyond image classification.
===============================================================================================================
Ji Lin*, Ligeng Zhu*, Wei-Ming Chen, Wei-Chen Wang, Chuang Gan, Song Han
Massachusetts Institute of Technology, MIT-IBM Watson AI Lab
NeurIPS 2022

On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offload the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.
===============================================================================================================
Han Cai, Chuang Gan, Ligeng Zhu, Song Han
Massachusetts Institute of Technology, MIT-IBM Watson AI Lab
NeurIPS 2020
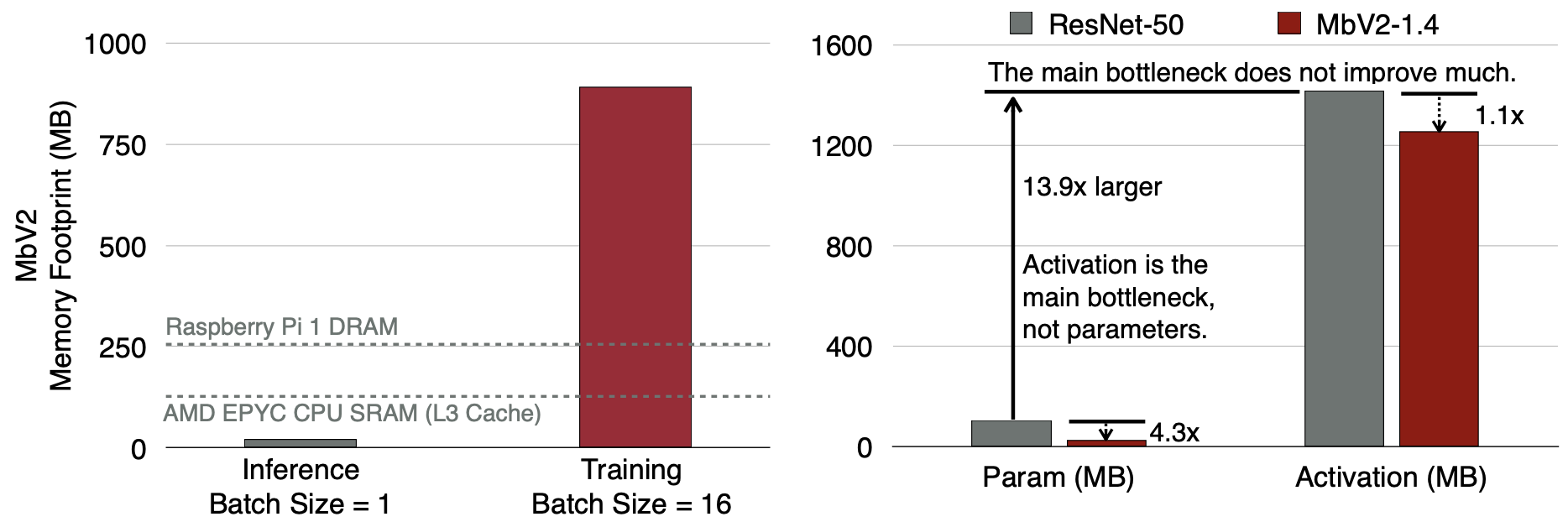
On-device training enables the model to adapt to new data collected from the sensors by fine-tuning a pre-trained model. However, the training memory consumption is prohibitive for IoT devices that have tiny memory resources. We propose an algorithm-system co-design framework to make on-device training possible with only 256KB of memory. On-device training faces two unique challenges: (1) the quantized graphs of neural networks are hard to optimize due to mixed bit-precision and the lack of normalization; (2) the limited hardware resource (memory and computation) does not allow full backward computation. To cope with the optimization difficulty, we propose Quantization-Aware Scaling to calibrate the gradient scales and stabilize quantized training. To reduce the memory footprint, we propose Sparse Update to skip the gradient computation of less important layers and sub-tensors. The algorithm innovation is implemented by a lightweight training system, Tiny Training Engine, which prunes the backward computation graph to support sparse updates and offload the runtime auto-differentiation to compile time. Our framework is the first practical solution for on-device transfer learning of visual recognition on tiny IoT devices (e.g., a microcontroller with only 256KB SRAM), using less than 1/100 of the memory of existing frameworks while matching the accuracy of cloud training+edge deployment for the tinyML application VWW. Our study enables IoT devices to not only perform inference but also continuously adapt to new data for on-device lifelong learning.
@inproceddings{lin2023awq,
title={AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration},
author={Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song},
booktitle={MLSys},
year={2024}
}
@InProceedings{xiao2023smoothquant,
title = {{S}mooth{Q}uant: Accurate and Efficient Post-Training Quantization for Large Language Models},
author = {Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song},
booktitle = {Proceedings of the 40th International Conference on Machine Learning},
year = {2023}
}
@inproceedings{zhu2023pockengine,
title={PockEngine: Sparse and Efficient Fine-tuning in a Pocket},
author={Zhu, Ligeng and Hu, Lanxiang and Lin, Ji and Wang, Wei-Chen and Chen, Wei-Ming and Han, Song),
booktitle={IEEE/ACM International Symposium on Microarchitecture (MICRO)},
year={2023}
}
@ARTICLE{10284551,
author={Lin, Ji and Zhu, Ligeng and Chen, Wei-Ming and Wang, Wei-Chen and Han, Song},
journal={IEEE Circuits and Systems Magazine},
title={Tiny Machine Learning: Progress and Futures [Feature]},
year={2023},
volume={23},
number={3},
pages={8-34},
doi={10.1109/MCAS.2023.3302182}
}
@article{lin2022ondevice,
title = {On-Device Training Under 256KB Memory},
author = {Lin, Ji and Zhu, Ligeng and Chen, Wei-Ming and Wang, Wei-Chen and Gan, Chuang and Han, Song},
booktitle={Annual Conference on Neural Information Processing Systems (NeurIPS)},
year = {2022}
}
@inproceedings{lin2021mcunetv2,
title={MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning},
author={Lin, Ji and Chen, Wei-Ming and Cai, Han and Gan, Chuang and Han, Song},
booktitle={Annual Conference on Neural Information Processing Systems (NeurIPS)},
year={2021}
}
@article{lin2020mcunet,
title={Mcunet: Tiny deep learning on iot devices},
author={Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Gan, Chuang and Han, Song},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
@inproceedings{
cai2020tinytl,
title={TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning},
author={Cai, Han and Gan, Chuang and Zhu, Ligeng and Han, Song},
booktitle={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}



